A Very Short Intro to Contextual Bandits
In the contextual bandits problem, we have an environment with K possible actions. The environment returns some context x, taken from a distribution X. The environment also has a function f(x, k), that calculates the reward based on the context and the chosen action k.
The goal then is to find the policy $\pi$ that maximizes the rewards obtained in the long-term. A policy is a function that maps contexts to actions.
The diagram below illustrates the problem:
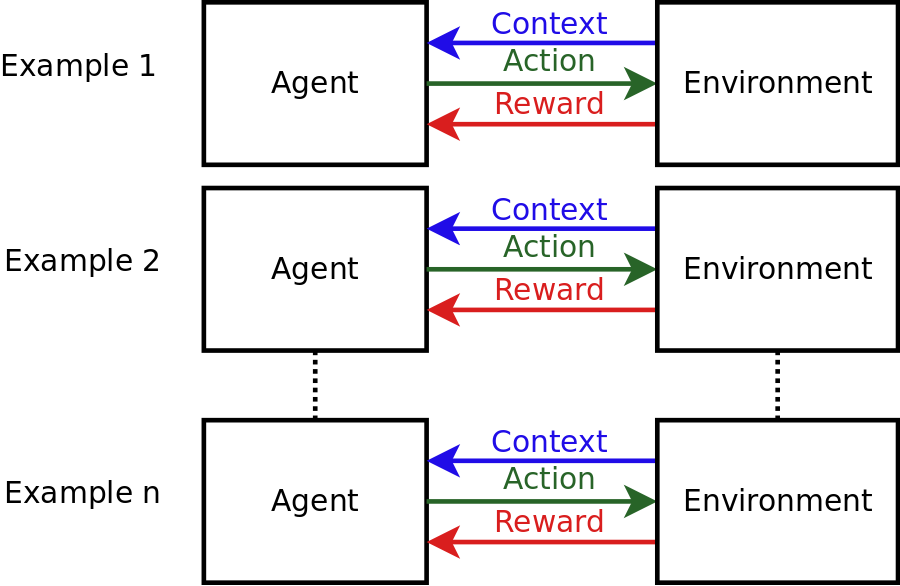
Explaining the steps:
- The environment displays a context x.
- The agent chooses an action k based on the observed context.
- The environment returns a reward based on the most recent context and action.
This process continues without a determined time-limit.
Additional considerations can be taken into account, like statistical efficiency (if the algorithm learns fast considering the number of examples) and computational complexity.
Example
- Agent: A doctor.
- Environment: Every day, a random patient comes into the hospital with a
disease X (the disease is the same to all patients).
- Context: Features of the patient like age, sex, etc.
- Actions: K-number of medicines that the doctor can prescribe.
- Reward: 1 if the patient was cured, 0 otherwise.
References
Slivkins, Aleksandrs. “Introduction to Multi-Armed Bandits.” ArXiv:1904.07272 [Cs, Stat], Sept. 2019. arXiv.org, http://arxiv.org/abs/1904.07272.