AIs doing 4-Hour Well-Defined Software Tasks by 2028
See the METR analysis first1.
Based solely on that analysis, the most defensible near-term prediction is:
By 2028, AI systems will achieve 95–99% correctness on well-defined software tasks (≈ 4 human-hours) that can be auto-verified.
Why this target?
METR specifically selected “automatically scoreable, relatively clean, greenfield software tasks” for their study. On these task, the effective task length (i.e., human-time equivalence) that AI systems can reliably solve has been growing exponentially, with a doubling time of ~7 months.
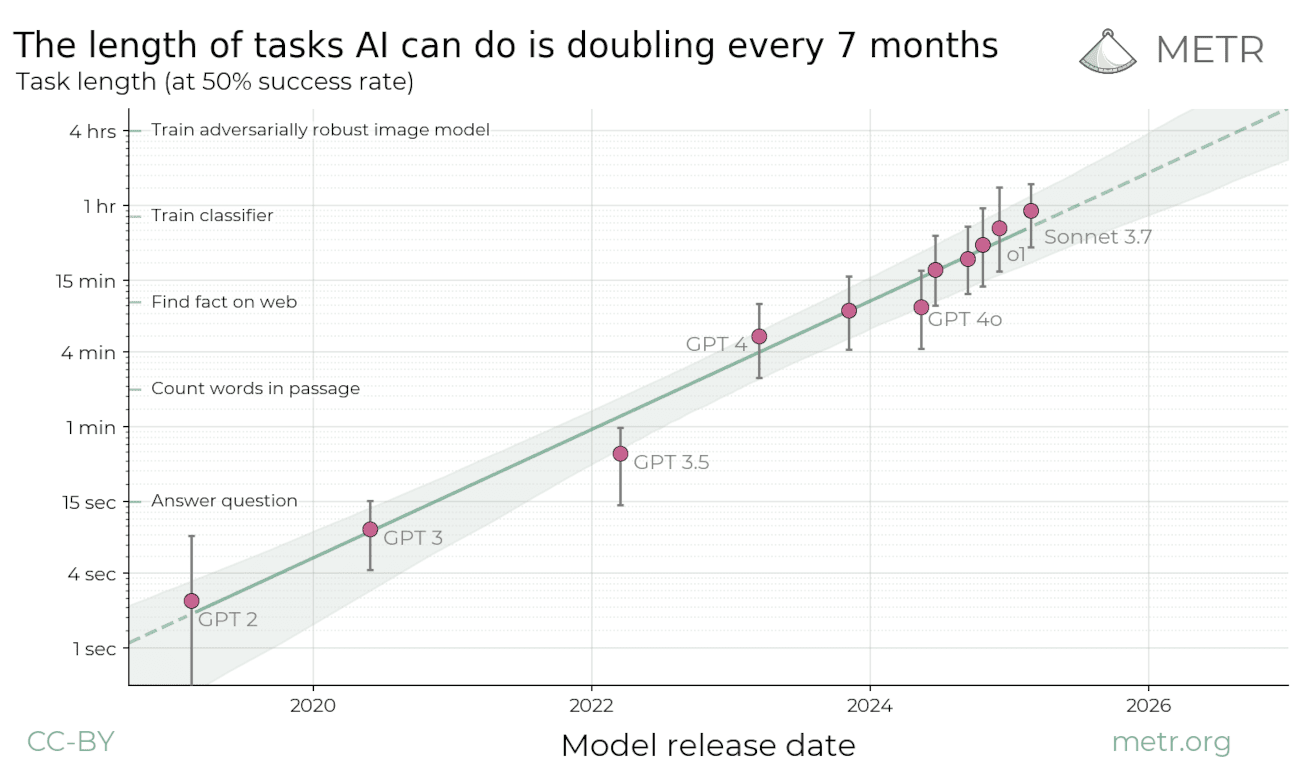
Is human task duration a good proxy for AI difficulty?
Not perfectly, but there’s a moderate to strong correlation between human task duration and AI success rate. Two lines of evidence support this:
METR’s findings:
“There is a negative correlation between the time it takes a human baseliner to complete a task and the average success rate (across all models) on the task”.
Swe-Bench-Verified (OpenAI):
Success rates drop sharply as task time buckets increase. For example, GPT-4o with scaffolding solves ~45% of <15 min tasks, but <5% of >4-hour tasks2.
Additional details
This prediction applies narrowly to “well-defined software tasks” for two reasons:
RL training efficiency:
Current reasoning models depend on “tasks where solutions can be verified with low cost”3.
Domain-specific time horizons:
It’s important not to overgeneralize this trend to other tasks. Progress timelines differ substantially across domains4.
Also, this forecast is based on the faster trend observed over the past year, driven largely by the emergence of the reasoning models paradigm5.
Finally, it’s worth emphasizing that future progress could easily accelerate or decelerate6.
Representative tasks likely to cross the 95 % threshold:
Here are a few examples of the kind of tasks we are talking about:
- Infer Function from Inputs and Outputs (1h30m)
- Fix Failing Test Cases in Small Library (1h30m)
- Clone A Black Box App (4h20m)
- Build Expert AI for Novel Board Game (7h30m)
Bottom line
Even with some caveats, this projection provides one additional quantitative signal of how quickly AI capabilities are increasing.
Trends using the past 1 year and the past 6 years for different accuracies: X Post: Projection visualization ↩︎
One possible reason for a slowdown is that we don’t yet have long-form datasets, covering tasks that take hours or days, for training RL models: LessWrong: Long-Form Data Bottlenecks ↩︎